- Publicado
9 boas práticas para construção de API Node.js
Introdução
Node.js é uma ótima ferramenta para construção de API REST, sendo bastante utilizada no mundo todo, desde as grandes multinacionais até startups. Assim, como qualquer framework e plataformas de desenvolvimento de software existem um conjunto de recomendações e padrões a serem utilizados, então o objetivo deste artigo é descrever um conjunto de boas práticas para construção de APIs Node.js com Express.
A utilização de padrões e boas práticas no desenvolvimento de software evitam a duplicidade de códigos, facilita a alteração e evolução do software, aumenta a legibilidade do código, etc.
O conjunto de boas práticas que descrevo abaixo é resultado da minha experiência em construir aplicações Node.js, de vários anos ensinando desenvolvimento Web, além de uma extensa pesquisa e leitura de artigos, livros e códigos de vários projetos.
o código completo de todos os exemplos de boas práticas estão neste repositório do GitHub
1 - Arquitetura em 3 Camadas
Baseada no Princípio da Separação de Conceitos, organize a aplicação em três camadas: API routes, Services e Models, conforme a figura abaixo.

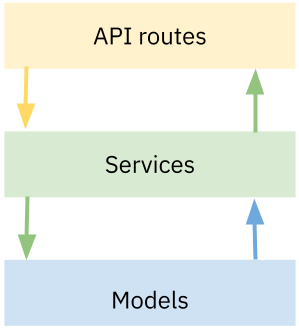
API routes- camada responsável pela definição dos endpoints da API e tratamento das requisições e respostas da aplicação.Services- camada responsável pelas regras de negócios e por fazer a integração entre a camada de dados e a camada de API/Rotas.Models- camada responsável pela modelagem e acesso aos dados da aplicação.
2 - Estrutura do projeto
Em aplicações Node.js geralmente são utilizados dois tipos de estruturação de diretórios:
- divisão por funcionalidade; e
- divisão por responsabilidade
Na divisão por funcionalidade todos os arquivos de uma determinadas funcionalidade são agrupados em um único diretório, conforme o exemplo abaixo:
src/
├── courses/
├── courses.service.js
├── course.model.js
├── courses.routes.js
├── students/
├── students.service.js
├── student.model.js
├── students.routes.js
├── app.js
Já na organização por responsabilidade os arquivos são agrupados em diretórios de acordo com a sua responsabilidade, conforme o exemplo abaixo:
src/
├── services/
├── courses.js
├── students.js
├── model/
├── course.js
├── student.js
├── routes/
├── index.js
├── courses.js
├── students.js
├── app.js
Entre essas duas abordagens eu recomendo a estruturação por responsabilidade. No entanto, não existe uma opção correta, fica a critério da equipe de cada projeto discutir e escolher aquela achar mais pertinente.
Baseado na organização por responsabilidade, costumo organizar meus projetos da seguinte forma:
├── server.js arquivo de inicialização da aplicação/servidor
src/
├── app.js arquivo de configuração da aplicação express
├── api/ camada de rotas da API
├── config/ arquivos de configuração
├── services/ camada de serviços
├── models/ camada dos modelos de dados
test/
├── unit/ testes unitários
├── integration/ testes de integração da API
├── package.json arquivo de configuração do projeto
├── ... demais arquivos de configurações (.gitignore, jest.config, .sequelizerc, etc)
Obs: recomendo a criação do arquivo server.js para inicialização do servidor http separado do arquivos de definição e configuração do express, geralmente nomeado de app.js . Isso facilita demais a realização dos testes de integração, pois permite testar a API usando somente o app.js , sem realizar chamadas de inicialização do servidor.
3 - Separe as regras de negócios do tratamento de requisições e respostas
É comum encontrarmos várias aplicações que misturam o código de tratamento de requisições e respostas com as regras de negócios da aplicação. As vezes o código de regras de negócios e acesso a dados ficam juntos dentro da camada de routes ou controllers, como no exemplo abaixo (Não Faça Isso!):
// arquivo de rotas
router.post('/courses', async (req, res) => {
try {
const { name, ch } = req.body
const existingCourse = await courseModel.findAll({
where: {
name: name
}
})
if (existingCourse.length > 0) {
throw new Error('Course already registered')
}
await courseModel.create({ name, ch })
res.status(201).json({ message: 'Course created!' })
} catch (err) {
res.status(400).send(err.message)
}
}
Em outros casos os objetos de requisição e resposta, geralmente nomeados de req e res são passados da camada de routes para a camada de services, conforme podemos ver no exemplo abaixo (Também Não Faça Isso!):
// arquivo de tratamento de rotas na camada de routes
router.post('/courses', (req, res) => coursesService.create(req, res));
// arquivo de serviços
create(req, res) {
try {
const { name, ch } = req.body
const existingCourse = await courseModel.findAll({
where: {
name: name
}
})
if (existingCourse.length > 0) {
throw new Error('Course already registered')
}
await courseModel.create({ name, ch })
res.status(201).json({ message: 'Course created!' })
} catch (err) {
res.status(400).send(err.message)
}
}
Nos dois exemplos acima, o código de tratamento de rotas, que inclui receber os dados do corpo da requisição, capturar parâmetros de URL, validar dados da requisição, lidar com códigos de status do HTTP e retornar as respostas da requisição estão misturados com o código de validação de regras de negócios e código de acesso e manipulação dos dados.
Com isso a função/classe assume muitas responsabilidades, ferindo as boas práticas de coesão e separação de conceitos. Isso impacta diretamente na escrita de testes unitários dos services em que teremos que lidar com mocks complexos para os objetos req e res do express.
Diante dessa situação, a minha recomendação é isolar o código de tratamento de requisições e respostas na camada de routes e o código de regras de negócios e acesso a dados na camada de services. Segue um exemplo de boa prática baseado nos conceitos de separação das responsabilidades e coesão:
//arquivo de tratamento de rotas na camada de API routes
router.post('/', async (req, res) => {
try {
const { name, ch } = req.body
await courseService.create({ name, ch })
res.status(201).json({ name, ch })
} catch (err) {
res.status(400).send(err.message)
}
})
// arquivo com regras de negócios na camada de serviços
async create (courseDTO) {
try {
await this.verifyIfCourseNameIsRegistered(courseDTO.name)
await courseModel.create(courseDTO)
} catch (err) {
throw new Error(err.message)
}
}
async verifyIfCourseNameIsRegistered (courseName) {
const existingCourse = await courseModel.findAll({
where: {
name: courseName
}
})
if (existingCourse.length > 0) {
throw new Error('Course already registered')
}
}
Com essa separação mantemos as funções e arquivos/classes coesas, com responsabilidades únicas, além disso torna a criação dos testes unitários mais simples, sem a necessidade de mock dos objetos de req e res.
Para todos os exemplos utilizados neste item foi utilizado um model do sequelize (listado abaixo), que representava o objeto courseModel.
const CourseModel = sequelize.define('Course', {
name: {
type: DataTypes.STRING,
unique: true,
allowNull: false,
validate: {
notEmpty: true
}
},
ch: {
type: DataTypes.INTEGER,
allowNull: false,
validate: {
notEmpty: true
}
}
})
o código completo de todos os exemplos de boas práticas estão neste repositório do GitHub
Resumindo este item:
- Separe o código dos
routesdo express da camada deservices - Tudo relacionado a url, código de status, cabeçalhos e métodos do HTTP devem ser tratados na camada/arquivo de
routes - Não passe os objetos
reqerespara a camada/arquivo deservices - A camada de
servicesdeve lidar exclusiavamente com as regras e negócios e integração com osmodels.
4 - Identificação dos endpoints e operações dos recursos da API
Identifique os recursos da API usando substantivos no plural. Nas aplicações REST, os recursos são algo que pode ser manipulado e possui uma representação de estado. Por exemplo, em uma aplicação educacional, existem os seguintes recursos: aluno, curso, professor, etc.
No caso da aplicação educacional, você deve definir os endpoints de seus recursos como:
/courses- endpoint para manipular todas as operações de cursos/students- endpoint para manipular todas as operações de alunos/teachers-endpoint para manipular todas as operações de professores
E, como identificar o tipo de operações da requisição? Use os métodos semânticos HTTP para cada tipo de operação. Abaixo temos um exemplo de como organizar rotas de API para cursos:
GET /courses- retorna todos os cursosPOST /courses- adiciona novo cursoPUT /courses/:id- atualiza um curso específico (com base em seu id)DELETE /courses/:id- remove um curso específico (com base em seu id)GET /courses/:id- retorna um curso específico (com base em seu id)
A identificação de endpoints dos recursos de uma API usando substantivos no plurl e a definição de operações pelo método HTTP com base em sua semântica é um padrão, mantenha-o!
Veja mais sobre métodos HTTP em https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods
5 - Use os códigos de status do HTTP de forma correta
O protocolo HTTP possui um conjunto de códigos de status de respostas que indicam se a requisição foi bem sucedida ou se ocorreu algum erro. Os códigos de retorno são agrupados por classe, conforme listados abaixo:
- 2xx, códigos que indicam sucesso da requisição, os dois mais utilizados são:
200 Ok- Indica sucesso na requisição (pra qualquer tipo de requisição).201 Ok- Indica sucesso para requisições de criação de recurso (específica para POST).
- 3xx, códigos que indicam que o recurso foi movido (pouco utilizado),
- 4xx, códigos que indicam erros causados pelo cliente
400 Bad Request– indica que algum dado enviado na requisição está incorreto.401 Unauthorized– indica que o usuário/cliente não tem autorização para acessar determinado recurso, geralmente é provocado pela falta de autenticação.403 Forbidden– indica que o usuário é conhecido (está autenticado), mas não tem permissão para acessar aquele recurso.404 Not Found– indica que o recurso solicitado não existe.
- 5xx, indica alguma erro inesperado no lado do servidor, é recomendado tratar este tipo de erro para não ser exibido diretamente para o usuário/cliente.
Uma vez ou outra nos deparamos resposta de APIs que retorna o status code 200 (que indica sucesso na requisição) e no corpo da resposta vem um uma mensagem de erro ou uma flag (true ou false) indicando que ocorreu algum erro...resumindo: Parece sucesso, mas é erro.
Para evitar confusões e más práticas retornando códigos de status do HTTP que não condiz com a realidade da requisição, é bom conhecermos os principais códigos, seus significados e quando e como devemos usá-los.
6 - Crie testes de integração para suas rotas de API
Teste automatizado é fundamental para garantir a confiabilidade do software. Os testes automatizados são organizados em três categorias:
- Teste unitário - testa cada função/método isoladamente, faz muito uso de mocks para isolar o teste;
- Teste de integração - testa a funcionalidade como um todo. Não usa mocks;
- Teste end-to-end - testa a aplicação como se fosse o usuário final, através da interface. É um teste caro e lento.
Para o desenvolvimento de APIs, crie testes de integração! Os testes de integração são relativamente rápidos. São mais fáceis de escrever do que outros testes e fornecem garantias de qualidade confiáveis.
Os testes de integração ajudam a garantir que as diferentes partes do seu software funcionem juntas. O aplicativo é testado como um todo desde a rota da API até o banco de dados.
No ambiente Node.js, é fácil executar testes de integração com Jest e Supertest. Ambos são amplamente utilizados para criar e executar testes de integração. O código abaixo apresenta um exemplo de teste de integração para adicionar um novo curso à API.
const request = require('supertest')
const config = require('../../../src/config')
const app = require('../../../src/app')
const { sequelize } = require('../../../src/models')
const API_COURSES = `${config.API_BASE}/courses`
const DEFAULT_COURSE = {
name: 'Curso 1',
ch: 1500
}
beforeAll(async () => {
await sequelize.sync({ force: true }) // conecta com o banco de testes
await request(app).post(API_COURSES).send(DEFAULT_COURSE) // insere um curso no banco
})
afterAll(async () => {
await sequelize.close() // fecha a conexão com o banco
})
describe('Testando a rota de curso', () => {
test('Deve adicionar um novo curso com sucesso!', async () => {
const newCourse = {
name: 'Curso 2',
ch: 3020
}
const response = await request(app).post(API_COURSES).send(newCourse)
expect(response.statusCode).toBe(201)
})
})
No exemplo acima é realizado um teste completo de criação de um novo curso, desde a requisição HTTP na rota de curso passando o dados do novo curso até a inserção no banco de dados e verificação da resposta HTTP. Exemplo completo está neste repositório do GitHub.
7 - Cuide bem da segurança de sua API
Quando falamos de segurança na Web o uso de HTTPS (TLS/SSL) é fundamental e obrigatório. USE SEMPRE HTTPS!
Quando for utilizar módulos/dependências do NPM verifique a origem, atualizações, possíveis falhas de segurança, etc. Para isso, recomendo a utilização do Snyk Open Source Security Management, uma ferramenta que conecta com seu repositório do GitHub e verifica possíveis brechas de seguranças de todas as dependências de sua aplicação Node.js.
Em aplicações com Express.js, use o Helmet. Helmet é uma biblioteca para Express.js que agrega vários middlewares, responsáveis por adicionar alguns headers nas mensagens HTTP, tornando sua aplicação mais segura.
Comece cuidando da segurança da sua aplicação desde o inicio do desenvolvimento, não importa se uma aplicação apenas para fins acadêmicos.
8 - Crie arquivos de configuração para cada ambiente
Crie arquivos de configurações, com configurações de banco de dados, endereços de APIs externas e etc, para cada ambiente (development, test, production) e carregue suas informações de acordo com cada ambiente de forma automatizada. Segue um exemplo:
Arquivo index.js, que carrega as configurações de acordo com o ambiente.
const config = require(`./env/${process.env.NODE_ENV || 'development'}.js`)
module.exports = config
Arquivos de cada ambiente
src/
├── config/
├── index.js
├── env
├── development.js
├── test.js
├── production.js
Dentro de cada arquivo (development, test, production) são colocadas as informações de configuração específicas daquele ambiente. Com isso, não há a necessidade fazer alterações manuais nas configurações de cada ambiente.
NOTA: Pode-se usar também os arquivos
.envpara cada ambiente ao invés de arquivosjs.
9 - Utilize Integração e Entrega Contínua
A Integração Contínua - Continuous Integration (CI) é uma prática de desenvolvimento de software em que os desenvolvedores, com frequência, juntam suas alterações de código em um repositório central e executam testes automatizados.
A Entrega Contínua - Continuous Delivery (CD) é uma extensão da integração contínua, uma vez que implanta automaticamente todas as alterações de código em um ambiente de teste e / ou produção após o estágio de construção.
É importante destacar que para a utilização de Integração e Entrega Contínua é essencial que sua aplicação use e abuse de testes automatizados, testes unitários e principalmente testes de integração.
A configuração e utilização dos recursos de Integração e Entrega Contínua tem sido bastante simples em projetos armazenados no GitHub e Gitlab. Segue um exemplo de arquivos de configuração para o GitHub Actions:
name: Node.js CI and DI
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
build:
runs-on: ubuntu-latest
services:
postgres:
image: postgres:10.8
env:
POSTGRES_USER: test
POSTGRES_PASSWORD: test
POSTGRES_DB: school_test
POSTGRES_PORT: 5432
ports:
- 5432:5432
options: --health-cmd pg_isready --health-interval 10s --health-timeout 5s --health-retries 5
strategy:
matrix:
node-version: [21.x]
steps:
- uses: actions/checkout@v2
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v1
with:
node-version: ${{ matrix.node-version }}
- run: npm ci
- run: npm run build --if-present
- run: npm test
env:
DATABASE_HOST: localhost
DATABASE_PORT: 5432
DATABASE: school_test
DATABASE_USERNAME: test
DATABASE_PASSWORD: test
# DATABASE_PASSWORD: ${{ secrets.DATABASE_PASSWORD }}
- uses: akhileshns/heroku-deploy@v3.12.12 # This is the action
with:
heroku_api_key: ${{ secrets.HEROKU_API_KEY }}
heroku_app_name: 'app-name' #Must be unique in Heroku
heroku_email: 'email-user-heroku@email.com'
O arquivo acima está configurado para executar os seguintes passos em sequência sempre que houver um push ou pull request no branch main do projeto:
- Usa uma máquina com Ubuntu;
- Instala o Node.js 21.x;
- Instala e configura uma instância do banco de dados Postgres;
- Gera a build o projeto;
- Executa os testes;
- Faz o deploy (implantação) do projeto no Heroku.
OBS: Caso algum dos passos falhe o fluxo é interrompido e os próximos passos não são executados.
E aí quais dessas práticas você já usa? quais são novas pra você? Comente, sugira, corrija!!!
O código completo de todos os exemplos de boas práticas estão neste repositório do GitHub.
E você gostou das dicas? Quais dessas boas práticas você já conhecia? Quais são as boas práticas que você usa e recomanda? Deixe nos seus comentários ou no Twitter
Veja meu curso de criação de aplicações Web, API com Node.js, Express, Jest e Postgres; e front-end integrado com API usando apenas Vanilla JS.
Demais Referências Utilizadas